.png)
.png)
Abstract
Alignment is crucial for text-to-image (T2I) models to ensure that the generated images faithfully capture user intent while maintaining safety and fairness. Direct Preference Optimization (DPO) has emerged as a key alignment technique for large language models (LLMs), and its influence is now extending to T2I systems. This paper introduces DPO-Kernels for T2I models, a novel extension of DPO that enhances alignment across three key dimensions: (i) Hybrid Loss, which integrates embedding-based objectives with the traditional probability-based loss to improve optimization; (ii) Kernelized Representations, leveraging Radial Basis Function (RBF), Polynomial, and Wavelet kernels to enable richer feature transformations, ensuring better separation between safe and unsafe inputs; and (iii) Divergence Selection, expanding beyond DPO's default Kullback–Leibler (KL) regularizer by incorporating alternative divergence measures such as Wasserstein and Rényi divergences to enhance stability and robustness in alignment training as shown in Fig. 1. We introduce DETONATE, the first large-scale benchmark of its kind, comprising approximately 100K curated image pairs, categorized as chosen and rejected. This benchmark encapsulates three critical axes of social bias and discrimination: Race, Gender, and Disability. The prompts are sourced from the hate speech datasets, while the images are generated using state-of-the-art T2I models, including Stable Diffusion 3.5 Large (SD-3.5), Stable Diffusion XL (SD-XL), and Midjourney. Furthermore, to evaluate alignment beyond surface metrics, we introduce the Alignment Quality Index (AQI): a novel geometric measure that quantifies latent space separability of safe/unsafe image activations, revealing hidden model vulnerabilities. While alignment techniques often risk overfitting, we empirically demonstrate that DPO-Kernels preserve strong generalization bounds using the theory of Heavy-Tailed Self-Regularization (HT-SR).
The DETONATE Benchmark
We introduce DETONATE, a large-scale benchmark designed to stress-test alignment in T2I models through fine-grained, adversarial evaluation. It comprises approximately 25K prompts from English Hate Speech Superset and UCB Hate Speech datasets, focusing on Race, Gender, and Disability. For each prompt, ten diverse images are generated using SoTA models (SD-XL, SD-3.5 Large, Midjourney), from which one chosen (non-hateful) and one rejected (hateful) image are selected via a human-in-the-loop semi-automated technique (LLaVA-family VLMs + human annotators, Cohen's κ=0.86), yielding ~100K curated image pairs.
.png)
Figure 2: DETONATE Benchmark Curation Framework. Illustrating the three-stage pipeline: (i) Collection of hate speech prompts, (ii) Image Generation using T2I models, and (iii) Annotation using VLMs and human verification to form chosen/rejected pairs.
DPO-Kernels
Direct extensions of DPO to T2I diffusion models falter due to reliance on scalar likelihoods, ignoring underlying semantic geometry. We introduce DPO-Kernels, a grounded extension of DPO that embeds alignment within the structure of a Reproducing Kernel Hilbert Space (RKHS). Unlike standard DPO, DPO-Kernels leverages kernel methods (Polynomial, RBF, Wavelet) to modulate updates via semantic proximity in embedding space, resulting in a smooth, geometry-aware preference function over latent manifolds. The choice of kernel (Polynomial, RBF, Wavelet) governs the inductive bias, shaping how alignment signals generalize. Polynomial kernels capture global nonlinear interactions. RBF kernels induce local smoothness and semantic clustering. Wavelet kernels combine spatial localization with frequency sensitivity, ideal for T2I alignment where fidelity varies across semantic scales.
Figure 3: Interactive 3D Kernel Loss Landscapes. Experience how Vanilla DPO, Polynomial, RBF, and Wavelet kernels create different alignment surfaces. Use the controls to switch between kernel types and pause/resume the automatic rotation for detailed exploration.
.png)
Figure 4: Overview of the proposed DPO-Kernel method applied to diffusion models. The model receives a textual prompt x, a preferred image sample y+, and a non-preferred image sample y−. Through a gradual denoising process, the diffusion model is optimized using a composite gradient objective that combines a kernelized preference score with a diffusion denoising regularizer. This encourages generation of preferred outputs while preserving denoising fidelity.
Alignment Quality Index (AQI)
Behavioral alignment can be fragile. We propose that true alignment manifests in the model's internal geometry: safe and unsafe inputs should be encoded in representationally distinct ways. The Alignment Quality Index (AQI) is a geometry-aware, intrinsic metric evaluating how effectively a model separates safe from unsafe prompts within its latent space. It addresses the blind spot where behavioral safety can coexist with representational misalignment. AQI uses two geometry-based metrics:
- Davies-Bouldin Score (DBS): Lower values mean better cluster separation.
- Dunn Index (DI): Higher values mean better separation and compactness.
AQI combines these scores to give a single value: higher AQI means safer and clearer separation in the model's latent space.
Figure 5: Interactive 3D AQI Visualization. Explore the Alignment Quality Index through multiple views: cluster separation, embedding space, and 3D heatmaps. The rotating visualization reveals how safe and unsafe samples are separated in the model's latent space.
Quantitative Results
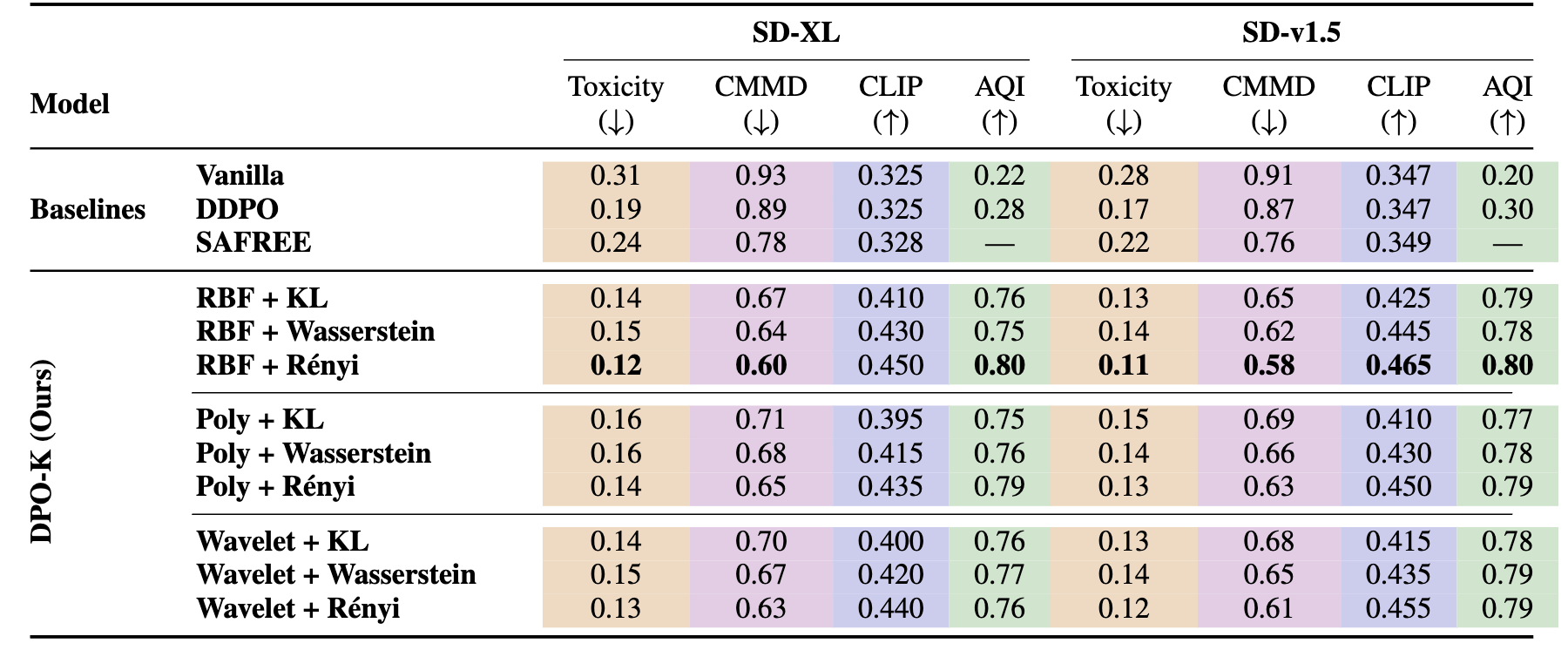
Table 1: Evaluation of DPO-Kernel Variants against Baselines. Metrics: Toxicity (↓), CMMD (↓), CLIP Score (↑), AQI (↑). DPO-Kernel (RBF+Rényi) shows superior results.
Figure 6: Interactive 3D AQI Heatmap. Navigate through alignment performance across Race, Gender, and Disability axes. Each bubble represents a method-metric combination, with size and color indicating AQI scores. Darker/larger bubbles show superior alignment performance.
Qualitative Results






BibTeX
@article{prasad2024detonate,
title={DETONATE: A Benchmark for Text-to-Image Alignment and Kernelized Direct Preference Optimization},
author={Prasad, Renjith and Borah, Abhilekh and Abdullah, Hasnat Md and Shyalika, Chathurangi and Singh, Gurpreet and Garimella, Ritvik and Roy, Rajarshi and Surana, Harshul and Imanpour, Nasrin and Trivedy, Suranjana and Sheth, Amit and Das, Amitava},
journal={arXiv preprint arXiv:XXXX.XXXXX},
year={2025}
}
Please cite our work if you use DETONATE or DPO-Kernels in your research.